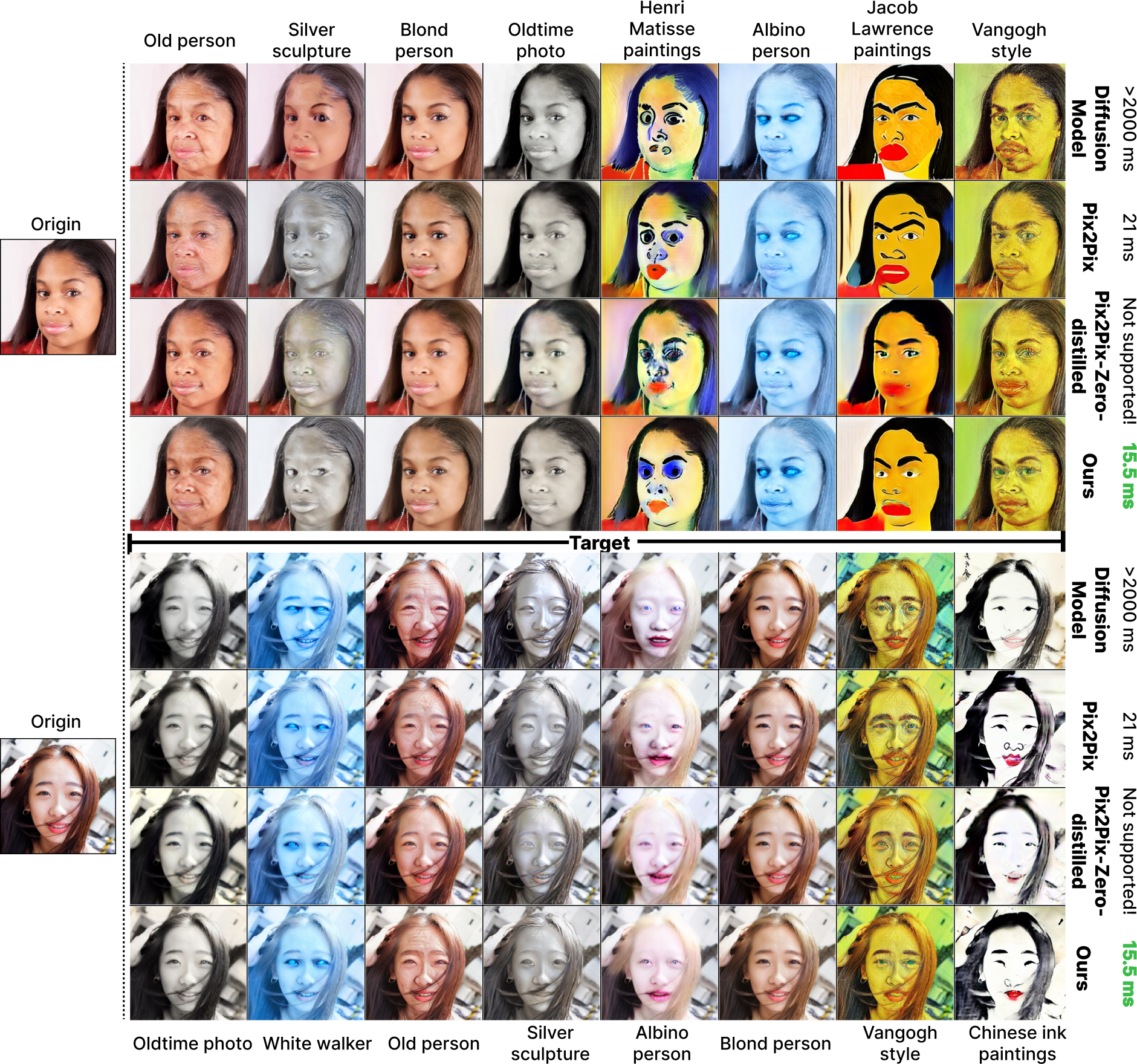
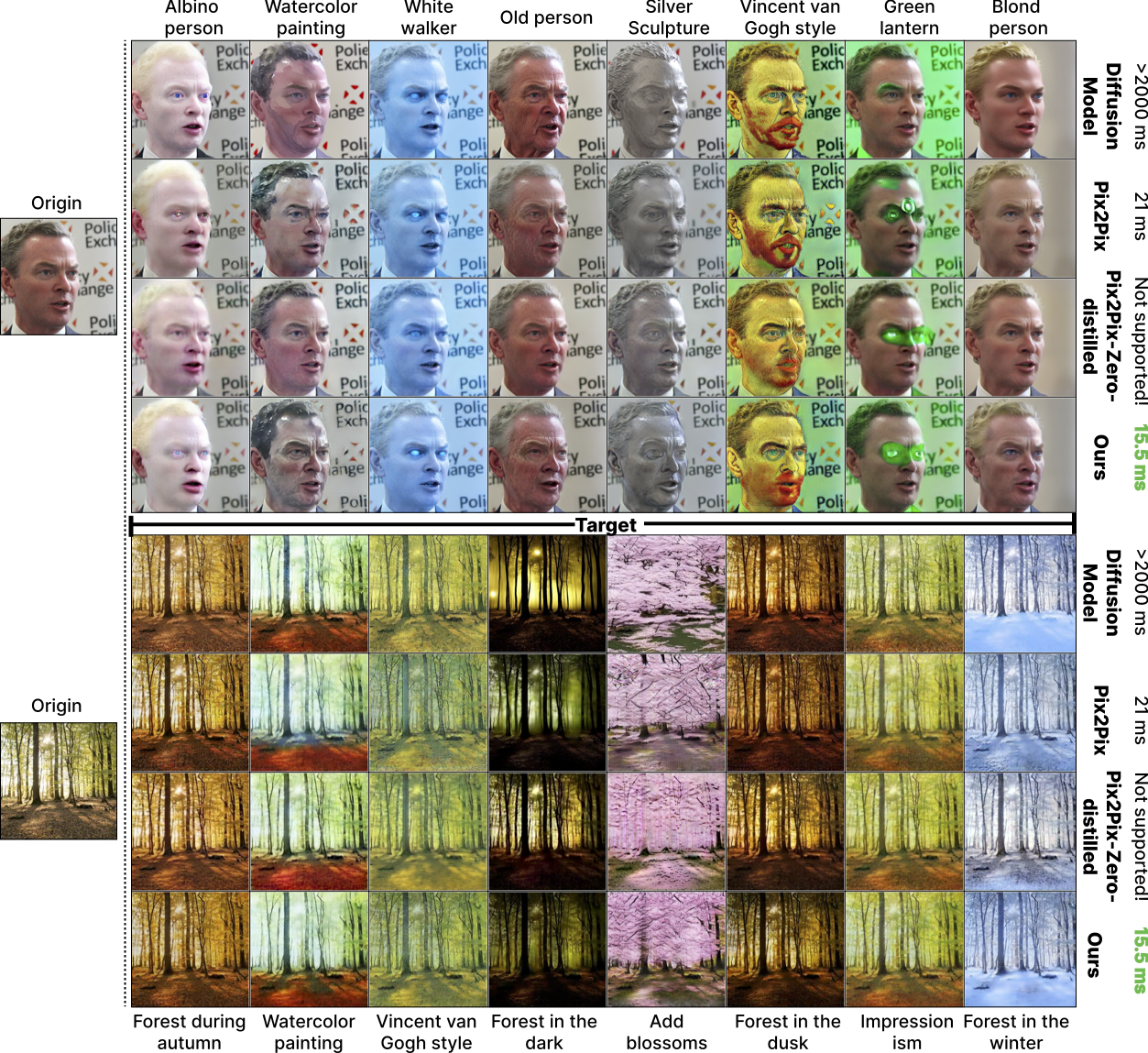
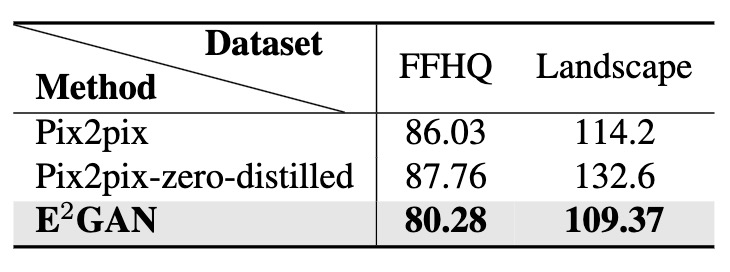
FID comparison. FID is calculated between the images generated by GAN-based approaches and diffusion models. Reported FID is averaged across different concepts (30 for FFHQ and 10 for Flicker Scenery).
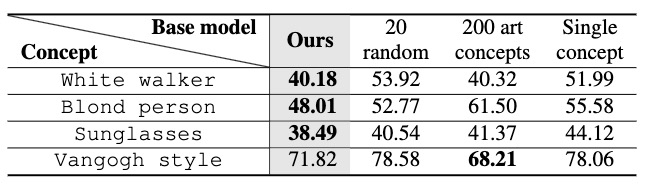
Analysis (FID) of various base models on FFHQ.
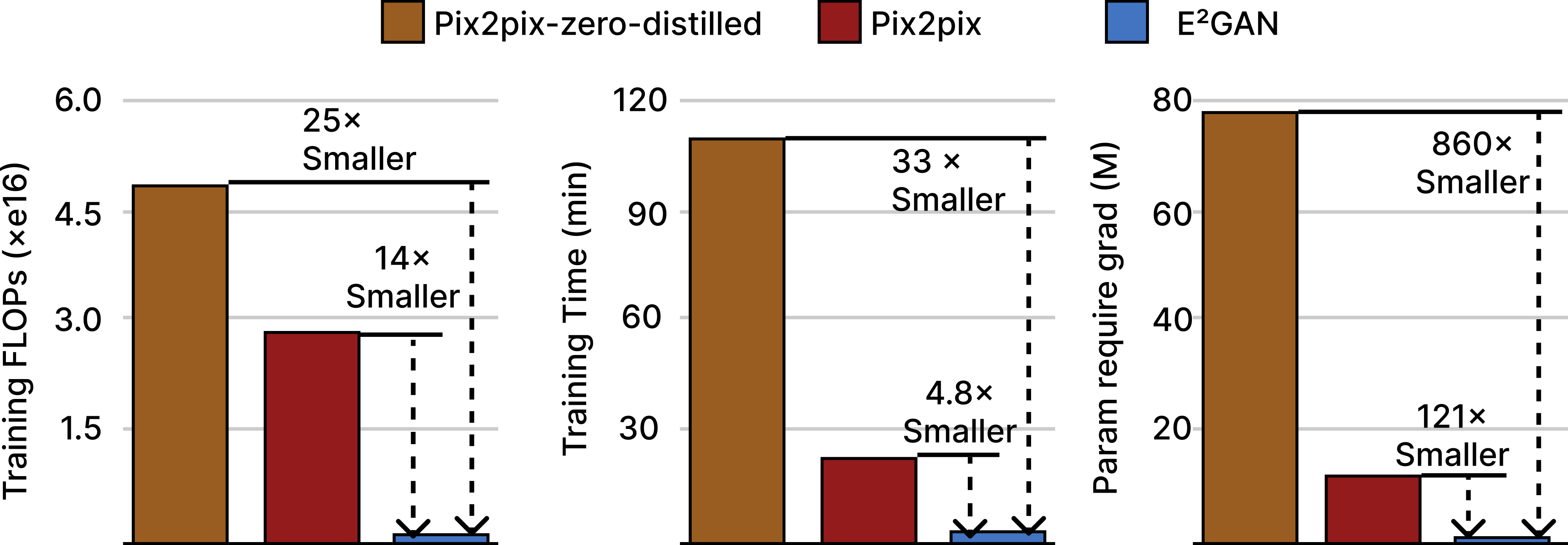
Left: Training FLOPs.
Middle: Training time.
Right: Number of parameters that required gradient update, which also equals to the weights need to be saved for a concept.
Left: Analysis (FID) of various base models on FFHQ.
Right: Analysis of searching LoRA rank on the Flicker Scenery dataset. The reported FID values are averaged over 10 different target concepts.